

ChatGPT受到廣泛的關注後,大語言模型受到大家廣泛的關注。Google 推出 7 堂完全免費的generative AI(生成式AI) 課程,包括介紹生成式 AI、介紹大型語言模型、注意機制、Transformer 模型和BERT 模型、介紹圖片生成、打造圖片描述模型、編碼器與解碼器架構,有興趣的人都可以免費學習。
- Introduction to Generative AI(介紹生成式 AI)
- Introduction to Large Language Models(介紹大型語言模型)
- Attention Mechanism(注意機制)
- Transformer Models and BERT Model(Transformer 模型和BERT 模型)
- Introduction to Image Generation(介紹圖片生成)
- Create Image Captioning Models(打造圖片描述模型)
- Encoder-Decoder Architecture(編碼器與解碼器架構)
大語言模型介紹
#2 介紹大語言模型,在這門課程中,將學習定義大型語言模型(Large Language Models, LLMs)、描述LLM使用案例。BTW,ChatGPT就是屬於大語言模型的一種。
LLMs和生成式AI相交,它們都是深度學習的一部分。大型語言模型指的是可以預先訓練並然後進行特定目的微調的大型通用語言模型。

預先訓練是什麼意思呢?想象一下訓練一隻狗狗,通常會教它基本命令,比如:坐下、過來、趴下和待在原地。這些命令通常足夠應對日常生活,然而如果需要一隻導盲犬就會增加特殊的培訓。類似的想法也適用於大型語言模型,這些模型被訓練用於「一般目的」,以解決常見的語言問題,比如文本分類、問答、文檔總結和跨行業的文本生成。

這些模型然後可以根據不同領域的需要進行定制,比如零售、金融和娛樂,使用相對較小的領域數據集。
讓我們更深入地探討大型語言模型的三個主要特點:
- 「大型」指的是兩個含義,首先是訓練數據集的巨大規模,有時達到PB(十的15次方)的量級。其次,它指的是模型的參數數量,在機器學習中,參數通常被稱為超參數,基本上是機器從模型訓練中學到的記憶和知識。
- 「通用目的」意味著這些模型足夠解決常見的問題。這是因為人類語言的普遍性,不論具體任務如何,以及資源限制,只有某些組織具有使用龐大數據集和大量參數訓練這種大型語言模型的能力。
有三種大型語言模型:通用語言模型、指令調整和對話調整,每種都需要以不同的方式進行提示。
通用語言模型根據訓練數據中的語言預測下一個詞。這是通用語言模型的一個例子,下一個詞是基於訓練數據中的語言的標記。在這個例子中,貓坐在下一個詞應該是“the”,你可以看到“the”是最有可能的下一個詞。這種類型可以看作是搜索中的自動完成。

在指令調整中,模型被訓練來預測對輸入中給出的指令的響應。例如,總結文本X、以X風格生成詩歌、基於語義相似性為X生成關鍵詞列表。
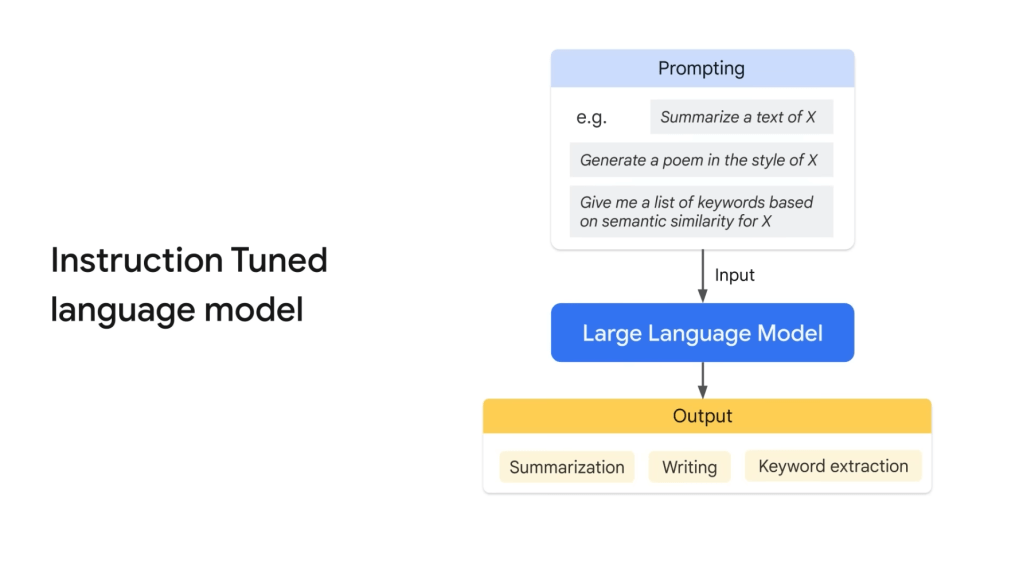
在對話調整中,模型被訓練來進行對話,根據下一個回應進行調整。對話調整模型通常是指令調整的一個特例,其中請求通常以對話的形式提出,對話調整預期在更長的來回對話上運作,通常對自然問題狀的表達效果更好。
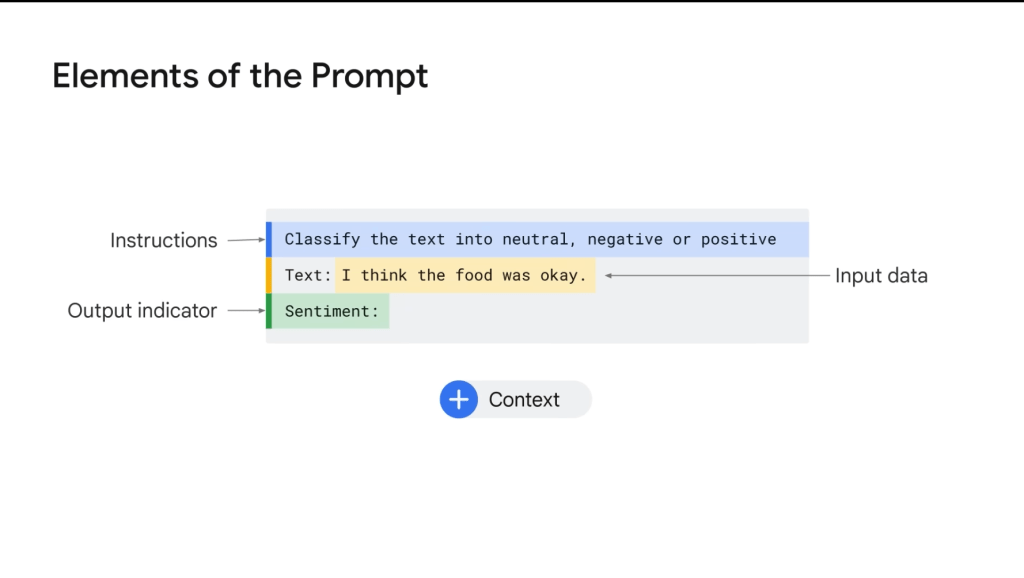
以上是關於Google #2介紹大語言模型的簡要介紹,大家可以發現大語言模型主要就是用來使用處理文字,所以像是在使用ChatGPT處理一些計算題目的時候比較容易出錯。不過,用來寫信、翻譯、提煉重點…等文字處理,目前的大語言模型已經能夠達到相當好的效果。

Yes 🔥🔥 good
讚讚